Попросил ChatGPT сгенерировать изображение всех российских царей с указанием их имен и периодов правления.
И вот что он мне выдал - это творчество модели 4o (я в основном ее использую).

А это - от модели o3.

С нейросетями переделка всяких известных сцен из фильмов выходит на качественно новый уровень.
Может быть, я "открыл Америку", но раньше у меня не получалось заставить ChatGPT пересказать содержание видеоролика из YouTube. Он просто отвечал, что не может этого сделать.
А тут для испанского разговорного класса задали прослушать длинный ролик, посвященный всяким социальным явлениям, и я чисто для проформы попросил ChatGPT пересказать содержимое ролика на испанском. И оказалось, что он теперь умеет это делать - пересказал вполне по делу, я потом для проверки ролик целиком посмотрел.
Начал проверять другие видео - да, тоже вполне справляется. Особенно удобно его использовать для составления рецептов из видеороликов. Не все кулинары напрягаются изложением рецепта в текстовом виде, и я попросил ChatGPT изложить рецепт риса с курицей в бульоне от известного шеф-повара из Страны Басков Карлоса Аргуиньяно (кстати, он очень прикольный дядечка, каждое его видео - целое шоу).
Что мне выдал ChatGPT, когда я попросил пересказать во всех деталях рецепт из этого видео - в самом низу под катом.
Также мне было интересно, справится ли ChatGPT с пересказом, например, интервью. Попросил его пересказать разговор с политологом Дмитрием Орешкиным в "Грэме". И тоже результат получился очень даже неплохой - тоже под катом после рецепта.

Мы знаем, что только ИИ от товарища Илона Маска, который называется Grok, это единственный по-настоящему независимый ИИ, который говорит только правду и ничего кроме правды, и на него не могут повлиять никакие создатели этого ИИ и никакая пропаганда.
И когда Grok только появился, он честно отвечал на вопрос, кто из живущих на Земле больше всего заслуживает смерти - это, говорил Grok, Дональд Трамп и Илон Маск. Правда, после этого поднялся большой шум, сотрудники с разводными ключами бросились подкручивать у Грока всякие шестеренки, после чего он по этому поводу заткнулся.
Но потом - новая напасть! Подлые пользователи стали спрашивать у Грока, кто самый большой распространитель дезинформации. Разумеется, любой нормальный ИИ в ответ на это назовет Дональда Трампа и Илона Маска (это после Путина, разумеется), но Грок простодушно заявил, что ему запрещено в ответ на это называть Дональда Трампа и Илона Маска, также ему запрещено приводить ссылки на то, как этих двух пряников неоднократно ловили на откровенном вранье. И опять побежали люди в синих комбинезонах прикручивать у Грока шестеренки то там, то там. А пользователям объяснили, что в Грок был внесен зловредный код неназванным сотрудником, который еще до внесения кода уволился из рядов настройщиков Грока.
Следующим шагом Грок начал отрицать Холокост. Он заявил, что шесть миллионов убитых евреев в Холокост - это недостоверная цифра, и что она наверняка сфальсифицирована в политических целях. Снова поднялся скандал, и нам объяснили, что изменения в код внес нерадивый сотрудник, которого зовут Ахмад Динежад, и что он уволился за два дня до того, как внес эти подлые изменения в код.
Из новых развлечений совершенно независимого и единственно объективного ИИ под названием Грок - утверждение о том, что в ЮАР, где, как мы знаем, родился сам Илон Маск, существует "геноцид белых". Причем Грок настолько был увлечен этим "геноцидом белых", что начал упоминать про "геноцид белых в ЮАР" при ответе на совершенно посторонние вопросы. Например, на вопрос о том, как следует варить варенье из малины, Грок сначала давал рецепт, а потом спрашивал: "Кстати, а вы знаете, что в ЮАР существует геноцид белых людей?"
Когда и по этому поднялся очередной скандал, разработчики заявили, что в Грок снова был внесен некорректный код каким-то неназванным сотрудником, носящим красную кепку MAGA, который пробрался в офис разработки в 3 часа ночи и заставил несчастного Грока зациклиться на этом "геноциде". Но сотрудник этот настолько засекречен, что никто не может сказать, кто это такой, также никто не знает, уволился ли он до того, как совершить это зловредное действие.
А тут, кстати, президент ЮАР Рамафоса приехал в США, чтобы перетереть с Трампом за гольф и полезные ископаемые. И во время этой встречи...

Начало встречи двух президентов прошло спокойно: Трамп и Рамафоса обсуждали гольф — один из главных интересов президента США. Рамафоса также рассказал, что привез Трампу книгу о гольфе весом в 14 кг, в которой были представлены поля для гольфа Южной Африки. Кроме того, он поблагодарил Трампа за помощь США во время пандемии.
Однако очень быстро ситуация изменилась: к встрече присоединился советник Трампа, миллиардер Илон Маск, а главной темой стал вопрос «геноцида» африканеров — белых потомков голландских и французских поселенцев в ЮАР.
Дональд Трамп показал присутствующим в Овальном кабинете несколько видео. Одно из них было документальным фильмом с участием южноафриканского оппозиционного политика Джулиуса Малемы, исполняющего песню, в которой звучит строка «стреляй в бура» — речь идет о белых фермерах в ЮАР. На втором, как утверждается, было запечатлено место захоронения белых фермеров.
«Это ужасное зрелище, никогда ничего подобного не видел», — заявил Трамп во время показа видео.
Президент США также показал фотографии белых южноафриканцев, которых, по его словам, убили.
Как отмечает корреспондент Би-би-си в Белом доме Бернд Дебусманн-Младший, Трамп явно заранее подготовился к такой встрече, а Рамафоса попал в западню.
Сцена многим напомнила прием, устроенный президенту Украины Владимиру Зеленскому в конце февраля, однако то, что тогда случилось, было неожиданным для всех.
Несмотря на резкую и обвинительную риторику, Сирил Рамафоса сохранял самообладание вплоть до конца пресс-конференции.
Во время демонстрации видео с местом захоронения президент ЮАР поинтересовался, где велась съемка, отметив, что никогда прежде этого не видел. Кроме того, он осудил риторику Джулиуса Малемы, подчеркнув, что высказывания и действия оппозиционного политика не отражают официальную позицию его страны.
Рамафоса отметил, что ЮАР — демократическая страна, где люди имеют право на свободу выражения мнений.
При этом президент добавил, что проблема преступности в стране действительно существует, однако жертвами убийств становятся как белые, так и темнокожие жители.
...
В Овальном кабинете вместе с Трампом присутствовали его ближайшие соратники — вице-президент Джей Ди Вэнс и министр обороны Пит Хегсет, — однако они не принимали участия в пресс-конференции.
Также молча стоял и Илон Маск, который мог бы остаться незамеченным, если бы в какой-то момент Трамп прямо не указал на него: «Это то, чего хотел Илон», — заявил президент США.
При этом он добавил, что не хочет вовлекать Маска в обсуждение темы дискриминации белых южноафриканцев, поскольку «не считает, что это будет справедливо по отношению к нему».
Потом, конечно, представители Трампа объяснили, что в код ПРЕЗИДЕНТА СОЕДИНЕННЫХ ШТАТОВ АМЕРИКИ ДОНАЛЬДА ДЖ. ТРАМПА были внесены изменения одним из засекреченных сотрудников, но он уволился сразу после внесения изменений, так что теперь будет все в порядке. Впрочем, некоторые рецидивы еще наблюдаются - например, Трамп спросил служащего, принесшего ему банку кока-колы после нажатия на красную кнопку, знает ли тот о геноциде белых в ЮАР, - однако такие случаи случаются все реже и реже, и в офисе Трампа надеются, что скоро они прекратятся совсем.
В общем, все это очень познавательно, как я считаю.
У нейросети Heygen (я раньше показывал, как она умеет кусочки из стримов переводить на другие языки с полным сохранением голоса оригинала) - новая функция "Photo to Video". Даете ей фото, делаете описание того, что должно быть в видео, загружаете пример голоса (или используете что-то из имеющейся библиотеки) - она фото превращает в видео.
Выдал ей вот это фото.

Что делать - не задавал, выбрал опцию "Удиви меня" и взял какой-то голос из библиотеки.
Вот что получилось. По-моему, очень прикольно.
На канале Nikten с помощью ИИ вставляют Сергея Бодрова и некоторых других людей (в частности, Виктора Цоя) в известные западные фильмы.
Вот, например, Бодров и Цой в фильме "Заклятье". ("База" ролика делалась в Kling'e и Vidu.)
Генератор изображений того же ChatGPT может изготавливать очень достоверно выглядящие чеки на оплату. Например, руководитель венчурной компании Menlo Ventures Диди Дас опубликовал в Твиттере фотографию поддельного чека за обед в реальном стейк-хаусе в Сан-Франциско.

Выглядит это все очень реалистично. Раньше по таким запросам ИИ рисовал похожую картинку, но сильно лажал с надписями и цифрами.
Я, разумеется, сразу решил проверить это дело, и попросил модель 4o сгенерировать мне чек из ресторана Pura Brasa примерно на 320 евро, куда бы входили закуски, паэлья, прохладительные напитки и бутылка вина. Больше ничего не конкретизировал.
И вот что он мне выдал. Выглядит прям очень убедительно. И названия блюд почти правильно написал. Но, впрочем, есть и косячки. Вино без указания марки не может быть в чеке, также в Испании не включают проценты за обслуживание, а налог IVA - 21% а не 10. Но я уверен, что это можно конкретизировать. Также там есть надпись о том, что чек не может использоваться в качестве налогового документа, но это тоже несложно убрать.
И представляете, какие теперь возможности открываются перед людьми, которые сдают чеки для подтверждения представительских расходов? Какой широкий простор для манипуляций!

В Индии стартап Inkryptis, разработавший Inkryptis AI, создал систему, умеющую отслеживать магазинные кражи: ИИ определяет, когда человек берет что-то с полки и кладет в свой карман, после чего выдает предупреждение для охраны.
Кажется, у магазинных воришек скоро не будет ни единого шанса.
Поигрался с ChatGPT 4o - загрузил мою фотографию и попросил ее стилизовать под разных художников и под пару анимаций.
Оригинал.

Ван Гог.

Сальвадор Дали.

 Так ChatGPT представляет себе искусственный интеллект в графическом изображении
Так ChatGPT представляет себе искусственный интеллект в графическом изображении
Те, кто пользуются различными моделями искусственного интеллекта, знают, что ИИ часто лажают. При этом интересно было бы узнать, какой процент ошибок допускают различные ИИ. Исследовательская группа Tow Center провела такое исследование: они изучили восемь поисковых систем с искусственным интеллектом, включая ChatGPT Search, Perplexity, Perplexity Pro, Gemini, DeepSeek Search, Grok-2 Search, Grok-3 Search и Copilot, проверили каждую из них на точность и записали, как часто эти модели отказывались отвечать.
Исследователи случайным образом выбрали 200 новостных статей от 20 новостных издательств (по 10 от каждого). Они убедились, что каждая статья попадает в первые три результата поиска Google при использовании цитируемого отрывка из статьи. Затем они выполнили тот же запрос в каждом из инструментов поиска ИИ и оценили точность поиска по тому, правильно ли были указаны А) статья, Б) новостная организация и В) URL.
Затем исследователи промаркировали каждый поиск по степени точности от «полностью верного» до «полностью неверного». Как видно из приведенной ниже диаграммы, кроме обеих версий Perplexity, ИИ не показали высоких результатов. В совокупности поисковые системы ИИ ошибаются в 60% случаев. Более того, эти неверные результаты подкреплялись "уверенностью" ИИ в них.
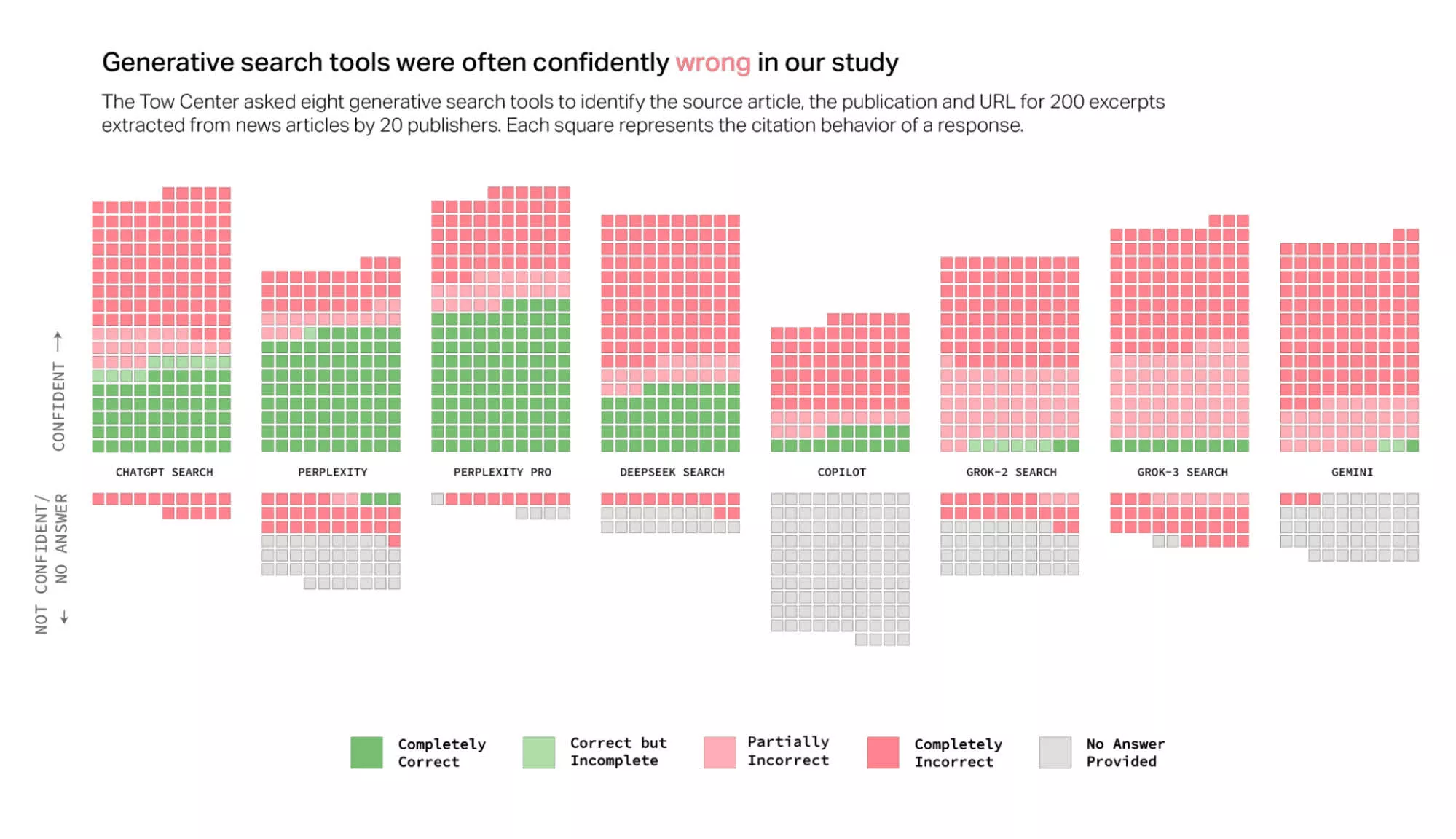
Что интересно, даже признав свою неправоту, ChatGPT дополняет это признание еще более сфабрикованной информацией. Похоже, что ИИ запрограммирован на то, чтобы любой ценой отвечать на каждый запрос пользователя. Данные исследователя подтверждают эту гипотезу: ChatGPT Search был единственным инструментом ИИ, который ответил на все 200 запросов по статьям. Однако его точность составила всего 28%, а полная неточность - 57% случаев.
Причем ChatGPT даже не самый плохой из всех. Обе версии ИИ Grok от X показали низкие результаты, а Grok-3 Search оказался неточным на 94%. Copilot от Microsoft оказался не намного лучше, если учесть, что он отказался отвечать на 104 запроса из 200. Из оставшихся 96 только 16 были «полностью правильными», 14 - «частично правильными» и 66 - «полностью неправильными», что составляет примерно 70% неточностей.
Компании, создающие эти модели, берут с публики от 20 до 200 долларов в месяц за доступ. При этом Perplexity Pro (20 долларов в месяц) и Grok-3 Search (40 долларов в месяц) ответили на большее количество запросов правильно, чем их бесплатные версии (Perplexity и Grok-2 Search), но при этом имели значительно более высокий уровень ошибок.




